
Solve your TensorFlow + Multiprocessing woes with forkserver
Even after decades of hacking with Python, I’m still learning new things. Recently I discovered the forkserver option in the multiprocessing library. This is a pretty obscure, low-level setting, but it solved some problems I’ve had trying to use TensorFlow with multiprocessing.
tl;dr
If you have problems with global state getting copied when you use multiprocessing, try switching the start method to forkserver.
What does multiprocessing do?
When you’re working in C++ or Java or whatever, you normally get parallelism by creating threads. Python also lets you create threads, but due to some details of the underlying interpreter implementation, Python code can’t really take advantage of multiple cores with extra threads. So the multiprocessing library supports parallelism by forking additional processes, rather than creating threads, and then you can make full use of all your CPU cores.
The multiprocessing library is pretty great, but sometimes the fact that you’re using extra processes instead of threads leaks through.
What’s inside a fork
In the UNIX family tree, the fork syscall creates an exact copy of a process, meaning all the contents of memory get duplicated. For example, suppose you allocate 4GB of memory, and then fork: then you have two 4GB processes, using a total of 8GB of memory.
import array
import os
# allocate an array of a billion 32-bit ints
x = array.array('l', range(1000000000))
# fork and make a copy of this proces
os.fork()
# now we have two processes, each with its own
# copy of this 4GB array
Of course the child process can then free the memory if it doesn’t need it, but you can see how this can get wasteful.
A thornier issue is that what you copy the memory, you also copy all the global state. You can carefully craft your own code to avoid relying on global state, but what about libraries?
Take TensorFlow for example. TensorFlow creates a default global session. For example, you can’t call set_visible_devices or set_logical_device_configuration after the TF session has been initialized; and executing pretty much any TF operation initializes the session. If you fork your process after initializing TensorFlow, the child process will have a copy of the same TF session as the parent, resulting in conflicts and weird exceptions when you try to use it.
This reflects an underlying physical reality: if you have just one GPU, and two different processes each think they have full control over it, they’re destined to stomp all over each other.
Why would you try to use TensorFlow with multiprocessing?
Let’s say I’m doing a deep reinforcement learning project, using some kind of asynchronous scheme. I have a bunch of CPU cores but only one GPU. The simulation and experience collection can run on the CPU, while I reserve the GPU for training. The experience collection is probably the bottleneck, so I want to run multiple agents in parallel, while having a single training process. I want to use multiprocessing to manage the whole pool.
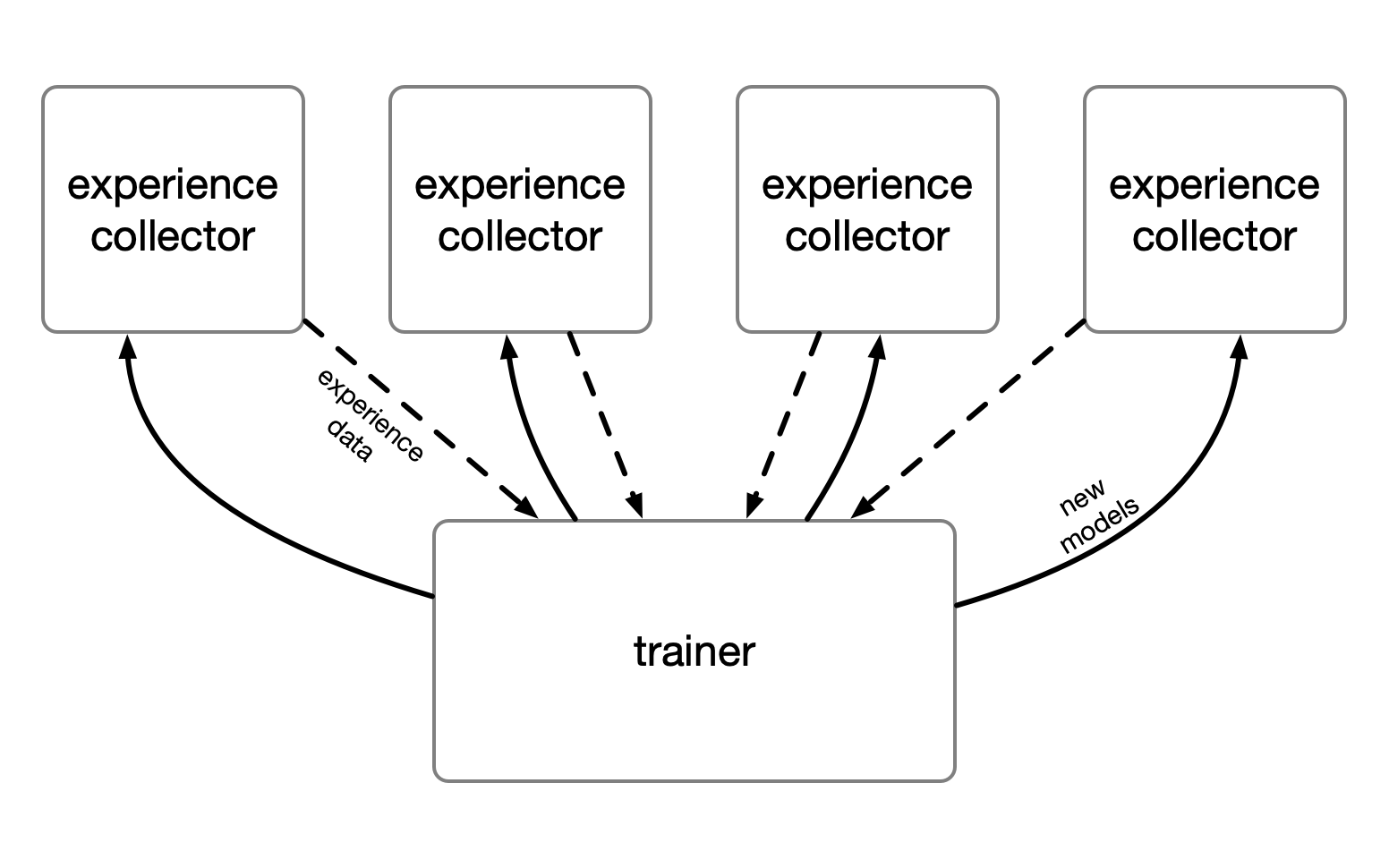
This is the typical setup where I would run into problems initializing TensorFlow on the experience workers. In the past, I dealt with it by carefully placing all TensorFlow imports so they only execute inside child processes. It’s quite tedious!
This is where forkserver comes in
The forkserver is a minimal Python process that sits around waiting for someone to use multiprocessing. When create a new process through multiprocessing, instead of immediately forking, it instead sends a message to the forkserver, and asks the forkserver to fork itself. So the child process is a copy of the forkserver, not the parent that asked for the child process! The point is that the forkserver doesn’t carry any of the parent’s baggage, so the child process starts with a clean slate.
You enable the forkserver by calling set_start_method:
multiprocessing.set_start_method('forkserver')
You want to do this as early as possible in your program. I like to put it in my entrypoint like this:
import multiprocessing
if __name__ == '__main__':
multiprocessing.set_start_method('forkserver')
run_the_actual_program()
Don’t rely on global state
Of course, using forkserver means any code that relies on global state will fail. For example:
import multiprocessing
MAGIC_NUMBER = 0
def child():
# Succeeds with `fork` method
# Fails with `forkserver` method
assert MAGIC_NUMBER == 1
def parent():
global MAGIC_NUMBER
MAGIC_NUMBER = 1
proc = multiprocessing.Process(target=child)
proc.start()
proc.join()
To solve this, pass in everything your child needs as arguments to its entrypoint:
import multiprocessing
def child(magic_number):
# Succeeds with any start method
assert magic_number == 1
def parent():
proc = multiprocessing.Process(
target=child,
args=(1,)
)
proc.start()
proc.join()
I’d argue the latter style is generally better, and will help you avoid surprises.
In conclusion
If you’re using TensorFlow with multiprocessing, just switch to forkserver and don’t look back.